
Kafka is an open source software for streaming data, which you can get more infomation about it here: https://kafka.apache.org
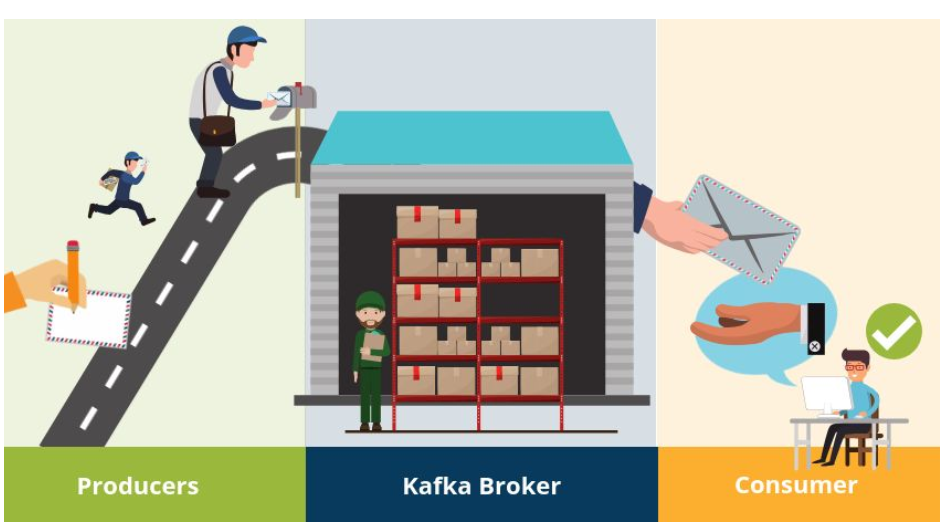
Apache Kafka is a publish-subscribe (pub-sub) message system that allows messages (also called records) to be sent between processes, applications, and servers. Simply said – Kafka stores streams of records.
A record can include any kind of information. It could, for example, have information about an event that has happened on a website or could be a simple text message that triggers an event so another application may connect to the system and process or reprocess it.
Unlike most messaging systems, the message queue in Kafka (also called a log) is persistent.
The data sent is stored until a specified retention period has passed by. Noticeable for Apache Kafka is that records are not deleted when consumed.
An Apache Kafka cluster consists of a chosen number of brokers/servers (also called nodes).
Apache Kafka itself is storing streams of records. A record is data containing a key, value and timestamp sent from a producer. The producer publishes records on one or more topics. You can think of a topic as a category to where, applications can add, process and reprocess
records (data). Consumers can then subscribe to one or more topics and process the stream of records.
Kafka is often used when building applications and systems in need of real-time streaming.
Topics and Data Streams
All Kafka records are organized into topics. Topics are the categories in the Apache Kafka broker to where records are published. Data within a record can be of various types, such as String or JSON. The records are written to a specific topic by a producer and subscribed from a specific topic by a consumer.
All Kafka records are organized into topics. Topics are the categories in the Apache Kafka broker where records are published. Data within a record can consist of various types, such as String or JSON. The records are written to a specific topic by a producer and subscribed from a specific topic by a consumer.
When the record gets consumed by the consumer, the consumer will start processing it. Consumers can consume records at a different pace, all depending on how they are configured.
Topics are configured with a retention policy, either a period of time or a size limit. The record remains in the topic until the retention period/size limit is exceeded.
Partition Kafka topics are divided into partitions which contain records in an unchangeable sequence. A partition is also known as a commit log. Partitions allow you to parallelize a topic by splitting the
data into a topic across multiple nodes.
Each record in a partition is assigned and identified by its unique offset . This offset points to the record in a partition. Incoming records are appended at the end of a partition. The consumer then maintains the offset to keep track of the next record to read. Kafka can maintain durability
by replicating the messages to different brokers (nodes).
A topic can have multiple partitions. This allows multiple consumers to read from a topic in parallel. The producer decides which topic and partition the message should be placed on.

PRACTICLE INSTALL KAFKA:
Installation
In this article, I am going to explain how to install Kafka on Ubuntu. To install Kafka, Java must be installed on your system. It is a must to set up ZooKeeper for Kafka. ZooKeeper performs many tasks for Kafka but in short, we can say that ZooKeeper manages the Kafka cluster state.
ZooKeeper Setup
- Download ZooKeeper from here.
- Unzip the file. Inside the conf directory, rename the file zoo_sample.cfgas zoo.cfg.
- The zoo.cfg file keeps configuration for ZooKeeper, i.e. on which port the ZooKeeper instance will listen, data directory, etc.
- The default listen port is 2181. You can change this port by changing
clientPort. - The default data directory is /tmp/data. Change this, as you will not want ZooKeeper’s data to be deleted after some random timeframe. Createa folder with the name datain the ZooKeeper directory and change the
dataDirin zoo.cfg. - Go to the bin directory.
- Start ZooKeeper by executing the command
./zkServer.sh start. - Stop ZooKeeper by stopping the command
./zkServer.sh stop.
Kafka Setup
- Download the latest stable version of Kafka from here.
- Unzip this file. The Kafka instance (Broker) configurations are kept in the config directory.
- Go to the config directory. Open the file server.properties.
- Remove the comment from listeners property, i.e.
listeners=PLAINTEXT://:9092. The Kafka broker will listen on port 9092. - Change log.dirs to /kafka_home_directory/kafka-logs.
- Check the
zookeeper.connectproperty and change it as per your needs. The Kafka broker will connect to this ZooKeeper instance. - Go to the Kafka home directory and execute the command
./bin/kafka-server-start.sh config/server.properties. - Stop the Kafka broker through the command
./bin/kafka-server-stop.sh.
Kafka Broker Properties
For beginners, the default configurations of the Kafka broker are good enough, but for production-level setup, one must understand each configuration. I am going to explain some of these configurations.
broker.id: The ID of the broker instance in a cluster.zookeeper.connect: The ZooKeeper address (can list multiple addresses comma-separated for the ZooKeeper cluster). Example:localhost:2181,localhost:2182.zookeeper.connection.timeout.ms: Time to wait before going down if, for some reason, the broker is not able to connect.
Socket Server Properties
socket.send.buffer.bytes: The send buffer used by the socket server.socket.receive.buffer.bytes: The socket server receives a buffer for network requests.socket.request.max.bytes: The maximum request size the server will allow. This prevents the server from running out of memory.
Flush Properties
Each arriving message at the Kafka broker is written into a segment file. The catch here is that this data is not written to the disk directly. It is buffered first. The below two properties define when data will be flushed to disk. Very large flush intervals may lead to latency spikes when the flush happens and a very small flush interval may lead to excessive seeks.
log.flush.interval.messages: Threshold for message count that is once reached all messages are flushed to the disk.log.flush.interval.ms: Periodic time interval after which all messages will be flushed into the disk.
Log Retention
As discussed above, messages are written into a segment file. The following policies define when these files will be removed.
log.retention.hours: The minimum age of the segment file to be eligible for deletion due to age.log.retention.bytes: A size-based retention policy for logs. Segments are pruned from the log unless the remaining segments drop belowlog.retention.bytes.log.segment.bytes: Size of the segment after which a new segment will be created.log.retention.check.interval.ms: Periodic time interval after which log segments are checked for deletion as per the retention policy. If both retention policies are set, then segments are deleted when either criterion is met.
