
Camera perception is one of the most important building blocks in a self-driving car. If radar tells us that something is there and LiDAR helps estimate geometry, the camera gives the system something equally valuable: semantic understanding. A camera can tell us what a traffic light means, what a road sign says, where lane markings curve, whether an object is a pedestrian or a bicycle, and whether a patch of road is drivable or blocked.
That is why modern autonomous-driving and ADAS systems still rely heavily on cameras, even when they also use radar, LiDAR, ultrasound, and maps. In practice, the camera is often the sensor that gives the richest visual context to the perception stack.

Why cameras matter so much
A self-driving vehicle does not just need distance. It needs meaning. The system must understand that a small red circle is a stop sign, that a green light means go, that a painted white line marks a lane boundary, and that a person at the curb may step into the road. These are tasks where cameras are especially strong because they capture texture, color, symbols, and shape in dense detail.
In real vehicles, cameras are used for tasks such as:
- lane detection and lane geometry estimation
- traffic-light and traffic-sign recognition
- object detection and classification for cars, trucks, bikes, and pedestrians
- free-space and drivable-area estimation
- visual odometry, localization, and mapping
- parking, surround view, blind-spot coverage, and driver monitoring
The practical advantage is cost and scalability. Cameras are relatively affordable, small, and information-rich, which is why many commercial ADAS platforms are camera-first or at least camera-centric. The limitation is that cameras are sensitive to bad lighting, glare, rain, fog, lens dirt, motion blur, and low texture. So the engineering question is not “camera or other sensors,” but rather “what should the camera do best, and what should be cross-checked by radar, LiDAR, or maps?”
How a camera sees the road
At the mathematical level, most automotive vision pipelines start with the pinhole camera model. A 3D point in the world is projected into a 2D pixel on the image plane. That sounds simple, but in practice you also need to account for lens distortion, focal length, principal point, camera pose, and synchronization with the rest of the vehicle.

Three ideas matter here:
- Intrinsics: focal lengths and principal point that describe how the lens and sensor map light into pixels.
- Extrinsics: the rotation and translation between the camera and the vehicle frame or world frame.
- Distortion: radial and tangential effects that bend straight lines unless the image is calibrated and rectified.
If calibration is poor, the whole stack becomes less trustworthy. Lane boundaries drift. Distance estimates become unstable. Multi-camera stitching looks wrong. That is why calibration is not a side issue; it is a core safety and reliability issue.
A small OpenCV-style example for undistortion looks like this:
import cv2 as cv
import numpy as np
image = cv.imread("front_camera.jpg")
camera_matrix = np.array([
[fx, 0, cx],
[0, fy, cy],
[0, 0, 1],
], dtype=np.float32)
dist_coeffs = np.array([k1, k2, p1, p2, k3], dtype=np.float32)
undistorted = cv.undistort(image, camera_matrix, dist_coeffs)
This does not solve perception by itself, but it gives the rest of the pipeline a cleaner and more geometrically meaningful image.
The practical camera pipeline in a self-driving car
Once the image is captured, the perception system usually follows a pipeline similar to this:
- Capture and synchronize. Frames must be time-aligned with other cameras, radar, IMU, wheel odometry, and vehicle state.
- Calibrate and rectify. Remove distortion and align the image to the vehicle geometry.
- Detect and segment. Use classical CV, deep learning, or both to extract lanes, drivable area, traffic lights, signs, and dynamic objects.
- Track over time. A single frame is noisy. Multi-frame tracking stabilizes detections and estimates motion.
- Estimate geometry. Recover depth from monocular cues, stereo disparity, multi-view triangulation, or fusion with radar/LiDAR.
- Fuse and decide. Combine camera output with other sensors and planning logic to support motion decisions.
This is the difference between a demo and a production system. A demo may detect a lane in one image. A production system must maintain stable, low-latency, safety-aware perception under changing weather, different roads, oncoming headlights, and partial occlusion.
What the camera is especially good at
Cameras are the strongest sensor when the system needs semantic detail. Here are the most important examples.
1. Lane understanding
Lane perception is more than finding two white lines. A useful system must estimate lane boundaries, lane center, curvature, merges, splits, missing paint, shadows, and construction zones. In older pipelines, engineers used color thresholding, edge detection, perspective transforms, and Hough lines. In modern systems, deep learning often handles lane segmentation or direct lane representation, but the classical ideas still matter because they explain the geometry and help with debugging.

In practice, lane perception supports downstream tasks such as lane keeping, trajectory generation, highway navigation, and safety envelopes around the vehicle.
2. Traffic lights and signs
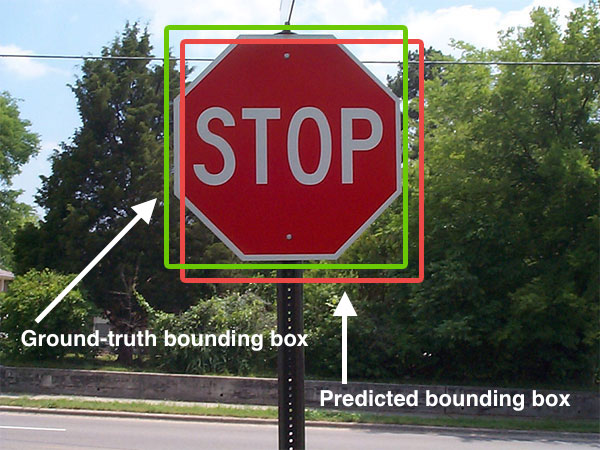
This is where cameras become indispensable. Radar cannot tell whether a light is red or green. LiDAR does not naturally read sign text or arrow direction. Cameras can. That makes them essential for semantic compliance with traffic rules.
A robust traffic-light stack must handle small objects at distance, occlusion, backlighting, LED flicker, and confusing urban scenes. A robust sign-recognition stack must classify signs correctly, but also decide whether a sign applies to the ego lane.
3. Object classification
Knowing that “something exists” is not enough. The planner needs to know whether that object is a pedestrian, cyclist, car, truck, cone, stroller, or road debris. Cameras provide the appearance cues that make this possible.
This is also where temporal reasoning matters. A pedestrian at the sidewalk is not the same as a pedestrian stepping into the crosswalk. The camera gives the appearance; tracking across frames gives intent clues.
4. Visual odometry and localization
Cameras are also useful for localization. By matching features across frames and across maps, the system can estimate motion and refine its position. This becomes even more powerful in stereo or surround-view configurations, or when fused with IMU and map information.
Monocular, stereo, and surround-view setups
Not all camera systems are the same.
- Monocular camera: cheapest and simplest, strong for classification and lane understanding, weaker for absolute depth unless combined with motion or learned depth cues.
- Stereo camera: adds geometric depth through disparity, especially useful at short and medium range.
- Surround-view multi-camera: provides near-360-degree coverage for parking, blind spots, intersections, and urban driving.

The key stereo idea is simple: a nearby object appears at different horizontal positions in the left and right image. That disparity can be converted to depth. In real systems, however, stereo only works well when calibration and rectification are correct, texture is sufficient, and weather or lighting does not destroy image quality.
Where cameras struggle
It is just as important to understand the limits of cameras.
- Night and low light: semantic detail drops and noise rises.
- Rain, fog, snow, glare: visibility degrades and the model sees less contrast.
- Dirty or blocked lenses: perception can fail locally even if the rest of the system is healthy.
- Motion blur and rolling shutter: fast motion distorts geometry.
- Depth ambiguity: monocular vision is weak at absolute metric depth without additional assumptions or fusion.
That is why production systems rarely trust a camera alone for all situations. Camera-first makes sense for semantics and scale, but sensor fusion still matters for robustness.
Why camera-first still makes sense
Even with those weaknesses, cameras remain central because they match several practical engineering goals at once:
- they capture dense visual information
- they are cheaper and easier to scale than high-end active sensors
- they support the semantic tasks that every road-legal system must solve
- they fit both ADAS and higher-autonomy stacks
That is why many commercial systems use a camera-first or camera-centric architecture, then add radar, LiDAR, maps, and driver monitoring where the safety case demands it.
A practical engineering checklist
If you are building or evaluating a camera-based perception stack, these are the questions that matter most:
- How stable is calibration over time, temperature, vibration, and mounting changes?
- What happens under glare, nighttime, rain, and lens contamination?
- How much latency exists from image capture to decision output?
- Which tasks are vision-only, and which require fusion?
- How is uncertainty represented and passed to planning?
- Does the system fail gracefully when the image quality drops?
Those questions usually separate a classroom demo from an automotive-grade perception module.
Conclusion
The camera is not just a passive eye on a self-driving car. It is the main source of semantic road understanding. It tells the system what the world means, not just where something is. That makes cameras essential for lane understanding, traffic-light recognition, sign reading, object classification, localization, and many driver-assistance functions.
At the same time, good camera perception depends on careful calibration, stable geometry, robust learning models, temporal tracking, and realistic handling of bad-weather and low-light failures. In other words, the power of cameras in autonomous driving is real, but it only becomes useful when the full engineering pipeline around the camera is strong.
References
- OpenCV camera model and calibration: https://docs.opencv.org/master/d9/d0c/group__calib3d.html
- OpenCV camera calibration tutorial: https://docs.opencv.org/4.x/dc/dbb/tutorial_py_calibration.html
- OpenCV stereo depth tutorial: https://docs.opencv.org/3.4/dd/d53/tutorial_py_depthmap.html
- Mobileye on camera-first assisted and autonomous driving: https://www.mobileye.com/blog/camera-first-approach-for-assisted-autonomous-driving/
- Mobileye on camera vision in ADAS: https://www.mobileye.com/blog/mobileyes-camera-vision-beyond-what-you-see/
- Mobileye Drive sensor configuration: https://www.mobileye.com/solutions/drive/
- Lane Detection: A Survey with New Results: https://www.sciopen.com/article/10.1007/s11390-020-0476-4?issn=1000-9000







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}