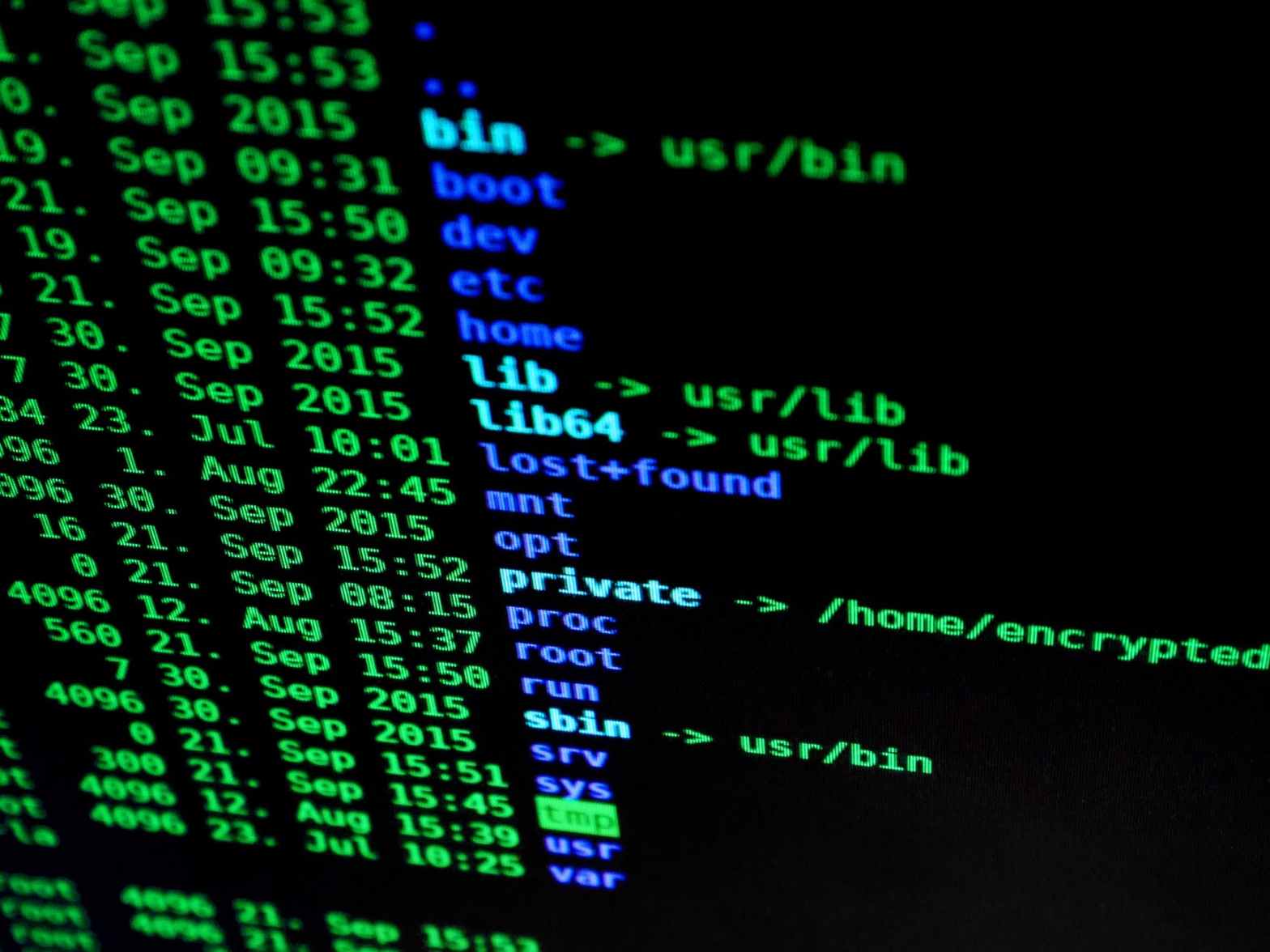
For Example to redirect the stdout to say a textfile, we could write
freopen ("text_file.txt", "w", stdout);
While this method is still supported in C++, this article discusses another way to redirect I/O streams.
C++ being an object-oriented programming language gives us the ability to not only define our own streams but also redirect standard streams. Thus in C++, a stream is an object whose behavior is defined by a class. Thus anything that behaves like a stream is also a stream.
Streams Objects in C++ are mainly of three types :
istream : Stream object of this type can only perform input operations from the stream
ostream : These objects can only be used for output operations.
iostream : Can be used for both input and output operations
All these classes, as well as file stream classes, derive from the classes: ios and streambuf. Thus filestream and IO stream objects behave similarly.
All stream objects also have an associated data member of class streambuf. Simply put streambuf object is the buffer for the stream. When we read data from a stream, we don’t read it directly from the source, but instead, we read it from the buffer which is linked to the source. Similarly, output operations are first performed on the buffer, and then the buffer is flushed (written to the physical device) when needed.
C++ allows us to set the stream buffer for any stream. So the task of redirecting the stream simply reduces to changing the stream buffer associated with the stream. Thus the to redirect a Stream A to Stream B we need to do
Get the stream buffer of A and store it somewhere
Set the stream buffer of A to the stream buffer of B
If needed reset the stream buffer of A to its previous stream buffer
We can use the function ios::rdbuf() to perform two opeations.
1) stream_object.rdbuf(): Returns pointer to the stream buffer of stream_object
2) stream_object.rdbuf(streambuf * p): Sets the stream buffer to the object pointed by p
Industrial robots are built for repeatability, precision, and productivity. They are common in manufacturing because they can perform structured tasks for long periods with consistent quality.
What an Industrial Robot Usually Looks Like
Many industrial robots are multi-joint robotic arms. They use motors, gear systems, controllers, and sensors to move a tool through space. That tool may be a gripper, a welding head, a camera, or a painting nozzle.
Common Applications
Welding: repeatable movement along a fixed path.
Pick and place: moving parts from one station to another.
Painting: smooth, controlled trajectories with good coverage.
Assembly: inserting or fastening components.
Inspection: using cameras or sensors for quality control.
Why Robots Are Useful
They reduce variation in repetitive processes.
They improve throughput.
They can work in environments that are dangerous or tiring for humans.
They make process timing easier to predict.
A Practical Engineering View
Using a robot well is not only about programming motion. It also involves cell layout, safety design, cycle time analysis, tooling, calibration, and maintenance. In many factories, the real challenge is system integration, not only robot control.
Example Workflow
A conveyor brings a part into a fixed position.
A vision system checks orientation.
The robot picks the part with a gripper.
It places the part in the next station with millimeter-level repeatability.
A PLC coordinates timing with the rest of the line.
Final Thoughts
Industrial robots are one of the clearest examples of engineering value in practice. They combine mechanics, electronics, control, and software into systems that solve real production problems every day.
According to inventor and artist Leonardo Da Vinci ‘Learning Never Exhausts the Mind’ and over the past decade here at SoftBank Robotics we have found that to be consistently true.
NAO History
In 2004 Aldebaran Robotics (Now SoftBank Robotics) launched project NAO which over time has come to revolutionize the way humans and robots interact with each other. NAO is a 58cm tall humanoid robot that is continuously evolving to help support humans in all their endeavors.
Capabilities
NAO’s abilities range from facial recognition, learning from past conversations to automated movement. NAO has already shown his more advanced capabilities through concierging at hotels, aided researchers in over 70 different institutions.
In Education
Most recently, NAO has been put to use in multiple South Australian schools; there NAO supports teachers, challenges students and is changing the way they interact. Monica Williams, a researcher from The Association of Independent Schools of South Australia noted that “What surprised the director was the depth of the students’ understanding and that once the teachers opened up to working with the students on the robot they continually saw things that surprised all of us as to what students were capable of”. Additionally, these schools found that both boys and girls were equally captivated by NAO and even began learning how to code for NAO using Python, an industry standard. Similarly, with the help of Choreographe and multiple licenses provided for schools, students can work with a virtual NAO as they take turns working with the actual NAO which encourages each student to learn at their own pace.
NAO has also been hard at work in the special education field, supporting students in developing skills like turn taking, spontaneous communication and social interaction with NAO and others.
Through the years, NAO has proven that whether you are a teacher wanting to empower your students, a hotel in need of a concierge or a student who could use a helping hand, NAO will be there for you, with capabilities that surprise and engage people.
NAO is more than just a robot, NAO can connect with real people and has the ability to become a core part of a community. Like us, NAO will keep developing and learning and if his time in Australia shows us anything, it is that NAO’s mind is far from exhausted.
Up till now, we have looked in Terraform for infrastructure provisioning and initial setup using provisioners. Now let’s look at ansible which is an open source automation platform. Ansible does configuration management, application deployment, along with infrastructure orchestration. Ansible is procedural rather than declarative. In ansible, we define what we want to do and ansible go through each and every step for that. In terraform, we specify what state we want to achieve and it makes sure we are at that state by creating, modifying or destroying needed resources. Ansible doesn’t manage any state so we need to define how we want to keep track of created resources using tags or other properties while terraform keeps the state of infrastructure so we don’t need to worry about duplicate resource creation. Personally, I recommend terraform for provisioning the infrastructure, and Ansible for configuring the software as terraform is much more intuitive for infrastructure orchestration.
Once upon a time, managing servers reliably and efficiently was a challenge. System administrators managed server by hand, installing software manually, changing configuration and managing services on servers. As managed servers grew and managed services become more complex, scaling manual process was time-consuming and hard. Then came Ansible which is helpful in creating the group of machines, define how to configure them, what action to be taken on them. All these configurations and actions can be triggered from a central location which can be your local system (named controller machine). Ansible uses SSH to connect to remote hosts and do the setup, no software needed to be installed beforehand on a remote host. It’s simple, agentless, powerful and flexible. It uses YAML in form of ansible playbook. Playbook is a file where automation is defined through tasks. A task is a single step to be performed like installing a package.
Ansible works by connecting to remote hosts (using SSH) defined in inventory file, which contains information about servers to be managed. Ansible then executes defined modules or tasks inside a playbook. Execution of playbook which is called the play. We can use predefined organised playbook called roles, which are used for sharing and reusing a provisioning.
Let’s have a look at some of the terminology used in ansible:
Controller Machine: Machine where Ansible is installed
Inventory: Information regarding servers to be managed
Playbook: Automation is defined using tasks defined in YAML format
Task: Procedure to be executed
Module: Predefined commands executed directly on remote hosts
Play: Execution of a playbook
Role: a Pre-defined way for organizing playbooks
Handlers: Tasks with unique names that will only be executed if notified by another task
As I am using Mac OS, so will be installing pip first using easy_install and then ansible using pip. Please look here to install for other platforms.
sudo easy_install pipsudo pip install ansible
Once above command executed, run command below to make sure that ansible is installed properly.
Ansible reads the ssh keys form ~/.ssh/id_rsa. We need to make sure we have public key setup on all remote hosts as we already done using terraform while creation of a remote EC2 instance.
For running ansible command, we need inventory file which is expected to be at a specified path: “/etc/ansible/hosts”. We can change its path using ansible config file (ansible.cfg file) in ansible workspace and define inventory file path there. We need to define username which we are going to use during ssh in ansible config file.
We can even create groups in the inventory file and execute ansible commands by replacing all with a group name. In below example, the server is our group name specified in the inventory file.
ansible server -m ping
Let’s look at playbooks to execute a series of actions. We need to make sure we define playbooks as idempotent so that they can run more than once without having any side effects. Ansible executes playbook in a sequential manner from top to bottom.
We are going to create a directory on our remote node using playbook for all hosts. Below mentioned playbook will create test directory in /home/ec2-user path.
When we execute above playbook using command “ansible-playbook playbook.yml” we get below result. In this, the first result is gathering facts. This happens as ansible executes a special module named “setup” before executing any task. This module connects to a remote host and gathers all kinds of information like IP address, disk space, CPU etc. Once this is done, our create directory task is executed to create the test directory.
There are many modules and commands available to be executed on remote hosts. With ansible, we can do a server setup, software installation and lot more tasks.
Welcome to the intro guide to Terraform! This guide is the best place to start with Terraform. We cover what Terraform is, what problems it can solve, how it compares to existing software, and contains a quick start for using Terraform.
If you are already familiar with the basics of Terraform, the documentation provides a better reference guide for all available features as well as internals.
What is Terraform?
Terraform is a tool for building, changing, and versioning infrastructure safely and efficiently. Terraform can manage existing and popular service providers as well as custom in-house solutions.
Configuration files describe to Terraform the components needed to run a single application or your entire datacenter. Terraform generates an execution plan describing what it will do to reach the desired state, and then executes it to build the described infrastructure. As the configuration changes, Terraform is able to determine what changed and create incremental execution plans which can be applied.
The infrastructure Terraform can manage includes low-level components such as compute instances, storage, and networking, as well as high-level components such as DNS entries, SaaS features, etc…
Examples work best to showcase Terraform. Please see the use cases.
The key features of Terraform are:
Infrastructure as Code
Infrastructure is described using a high-level configuration syntax. This allows a blueprint of your datacenter to be versioned and treated as you would any other code. Additionally, infrastructure can be shared and re-used.
Execution Plans
Terraform has a “planning” step where it generates an execution plan. The execution plan shows what Terraform will do when you call apply. This lets you avoid any surprises when Terraform manipulates infrastructure.
Resource Graph
Terraform builds a graph of all your resources, and parallelizes the creation and modification of any non-dependent resources. Because of this, Terraform builds infrastructure as efficiently as possible, and operators get insight into dependencies in their infrastructure.
Change Automation
Complex changesets can be applied to your infrastructure with minimal human interaction. With the previously mentioned execution plan and resource graph, you know exactly what Terraform will change and in what order, avoiding many possible human errors.
Programming an autonomous vehicle is not about writing one large script that makes a car drive by itself. It is about building a structured software stack where perception, localization, prediction, planning, and control work together in real time.
Start with the System, Not the Hype
If you want to build autonomous vehicle software, start by understanding the major layers of the system:
Perception: detect and track the environment.
Localization: estimate where the ego vehicle is.
Prediction: forecast what other agents might do.
Planning: choose the vehicle's future path and behavior.
Control: execute that path using steering, throttle, and brake.
A Good Learning Path
1. Learn in Simulation First
Simulators are ideal because they let you repeat experiments safely. Tools such as CARLA, Gazebo, or simulator environments from online courses are very useful for early learning.
2. Implement Small Modules
Do not try to build the full stack at once. Start with one module at a time:
lane detection,
PID steering control,
basic object detection,
pure pursuit path tracking,
simple occupancy-grid planning.
3. Connect the Modules
The hard part is not only making each module work. It is making them exchange the right information at the right time and with the right assumptions.
A Practical Example Project
A very good starter project is lane following in simulation:
Use a front camera image.
Detect lane boundaries with computer vision or a learned model.
Estimate the lane center relative to the ego vehicle.
Use a controller to generate steering commands.
Evaluate stability, overshoot, and robustness under noise.
This teaches perception, estimation, and control in one compact workflow.
Languages and Tools
Python for rapid prototyping and ML workflows
C++ for performance-critical components
ROS or ROS 2 for modular robotics software
OpenCV for computer vision
NumPy / PyTorch / TensorFlow for numerical and learning tasks
Final Thoughts
The best way to program an autonomous vehicle is to build understanding module by module, then integrate carefully. Real autonomy is a systems engineering discipline, and the engineers who succeed in it are usually the ones who respect both theory and integration detail.
Wikipedia defines Robot as a machine capable of carrying out complex series of actions automatically. The advantages and importance of Robots are contentious, the robotics field is evolving every day and the benefits of robots are becoming inevitable. This article is not meant to discuss the advantages of robots, but to get you started with ROS(Robot Operating System).
This article describes ROS installation, file system, packages, nodes, topics, messages, service, publishers, subscribers, and ROS GUI tools. The programming language used in this article is Python. Refer to this github repo for the codes in this article.
ROS is an open-source meta operating system or a middleware used in programming Robots. It consists of packages, software, building tools for distributed computing, architecture for distributed communication between machines and applications. It also provides tools and libraries for obtaining, building, writing, and running code across multiple computers. It can be programmed using python, c++, and lisp.
ROS vs Framework vs OS(Operating System)
Operating System(OS) manages communication between computer software and hardware. In the process of managing this communication, it allocates resources like the central processing unit(CPU), memory, and storage. Examples are windows, Linux, android, mac OS, etc.
Framework in computer programming is an abstraction in which software providing generic functionality can be selectively changed by additional user-written code, thus providing application-specific software. Software frameworks may include support programs, compilers, code libraries, toolsets, and application programming interfaces(APIs) that bring together all the different components to enable the development of a project or system. Examples are Django, Laravel, Tensorflow, Flutter, etc.
Robot Operating System(ROS) is not a full-fledged operating system, it is a “meta operating system”. It is built on top of a full operating system. It is called an OS because it also provides the services you would expect from an operating system, including hardware abstraction, low-level device control, implementation of commonly-used functionality, message-passing between processes, and package management. It is a series of packages that can be installed on a full operating system like Ubuntu.
ROS level of concepts
Filesystem level — these are resources located on the disk. For example, packages, package manifests (package.xml), repositories, messages types, service types, etc.
Computation level — these involve the communications between peer to peer networks of ROS. Examples are nodes, master, parameter server, messages, topics, services, bags.
Community level — these involve the exchange of software and knowledge between members of the community. Examples are distributions, repositories, ROS wiki.
catkin is the new build system (generate executable files from source files) for ROS while rosbuild was the build system used in the past. catkin uses CMake more cleanly and only enhances CMake where it falls short on features, while rosbuild uses CMake but invokes it from Makefiles and builds each package separately and in-source. catkin was designed to be more conventional than rosbuild, allowing for better distribution of packages, better cross-compiling support, and better portability.
ROS Distributions, Installation, and File System
ROS distributions are named alphabetically. For instance, the last 3 distributions are Lunar Loggerhead, Melodic Morenia, and Noetic Ninjemys. ROS can be officially built on Linux distributions but it also supports other operating systems. This article uses ROS Melodic distribution on Ubuntu 18 Linux distribution.
You can install other distributions by changing the distribution name. For instance, you can change melodic to noetic but note noetic support Ubuntu Focal Fossa(20.04). This installation installs the full version, you can install smaller versions for instance:
This installation does not contain the GUI tools.
After proper installation, you need to source the ROS setup script. source command reads and executes commands from the file specified as its argument in the current shell environment.
To avoid sourcing the setup file every time a new terminal is opened, you can add the command to the .bashrc file. It will automatically run when you open a new terminal.
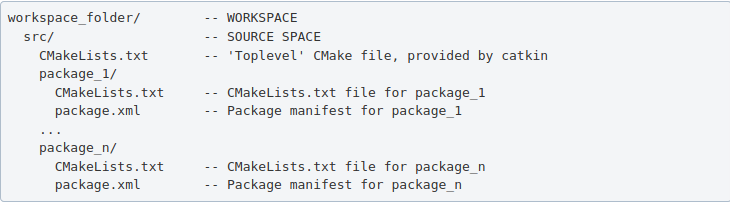
ROS packages are saved in a catkin “workspace” folder. The package folders are saved in the “src” folder in the catkin “workspace”.
The catkin_make command builds all packages located in “catkin_ws/src” folder. After running catkin_make command, two new folders “build” and “devel” will be created. Note, you should always run catkin_make command when you are in the “catkin_ws” directory. The “build” folder is where CMake and Make are invoked, while the “devel” folder contains any generated files and targets, including setup.sh files. A “CMackeLists.txt” file is also created in the src folder(I explained more about this file below).
Ros Package — contains libraries, executables, scripts, and other artifacts for a specific ROS program. Packages are used for structuring specific programs. Files in a package also have a specific structure. A ROS package folder could contain:
launch folder — it contains the launch files(launch files are used to run multiple nodes).
src folder — it contains the source files for instance python or c++ files.
package.xml — also called manifest file, contains package metadata, dependencies, and other metadata related to the package.
CMakeLists.txt -it contains executables, libraries, etc. it is catkin metapackage.
A ROS package must be in the parent “catkin_ws/src” folder, its folder, and must contain package.xml and CmakeList.txt.
Creating a ros package
This command creates a package called “bio_data_package” with dependencies std_msgs, rospy, and roscpp. This command automatically creates a folder named the package name, this package folder contains the “package.xml”, “CMakeLists.txt”, “include” folder and “src” folder. The “src” folder in the workspace folder is different from the “src” folder created in the package folder. Build all the packages in “catkin/src” by running catkin_make, source the “setup.bash” in the “devel” folder to add new environment variables.
ROS Package command-line tool — rospack
rospack is used to get information about packages. Note: Tab completion, press the tab key once to complete a command, and twice to show you suggestions. For instance, you press tab twice after rospack.
rospack list — list all the ROS packages in your workspace rospack find bio_data_package — to output the path of package “bio_data_package”
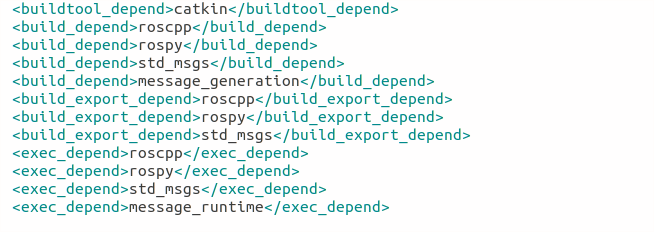
The package.xml contains tags that describe the package. The required tags are name, version, description, maintainer and license.
<name> – the name of the package.
<version> – the version of the package, usually it should be three integers separated by dots.
<description> – a description of the package.
<maintainer> – information about the maintainer i.e someone you can contact if you need more information about the package.
<license> – the license to the package.
<buildtool_depend>(build tool dependency) – the build system required to build the package, this is usually catkin or rosbuild.
<build_depend>(build dependency) – the dependencies of the package, each dependency is enclosed in a build_depend tag.
<build_export_depend>(build export dependency) – a dependency that is included in the headers in public headers in the package.
<exec_depend>(Execution Dependency) – a dependency that is among the shared libraries.
<test_depend>(Test Dependency) – a dependency required for unit test.
<doc depend>(Documentation Tool Dependency) – a dependency required to generate documentation.
A ROS node is an executable that uses ROS to communicate with other nodes. The concept of ros node helps in fault tolerance as each node does not depend on another node.
ROS Master — provides naming and registration services to the rest of the nodes in the ROS system. Publishers and Subscribers register to the master, then ROS Master tracks ROS topics being published by the publisher and ROS Topics being subscribed to by the subscribers. It also provides the Parameter Server.
rosout — rosout is the name of the console log reporting mechanism in ROS. rosout subscribes to /rosout topic.
Parameter Server — is a shared, multi-variate dictionary that is accessible via network APIs. Nodes use this server to store and retrieve parameters at runtime.
roscore — master + rosout + parameter server. It controls the entire ROS system. It must be running to enable ROS nodes to communicate. It is a collection of nodes and programs that are pre-requisites of a ROS-based system.
Once roscore is running, you can open a new terminal to run other ros nodes.
ROS node command-line tool — rosnode
ROS Run
rosrun — this is used to run a node in a package
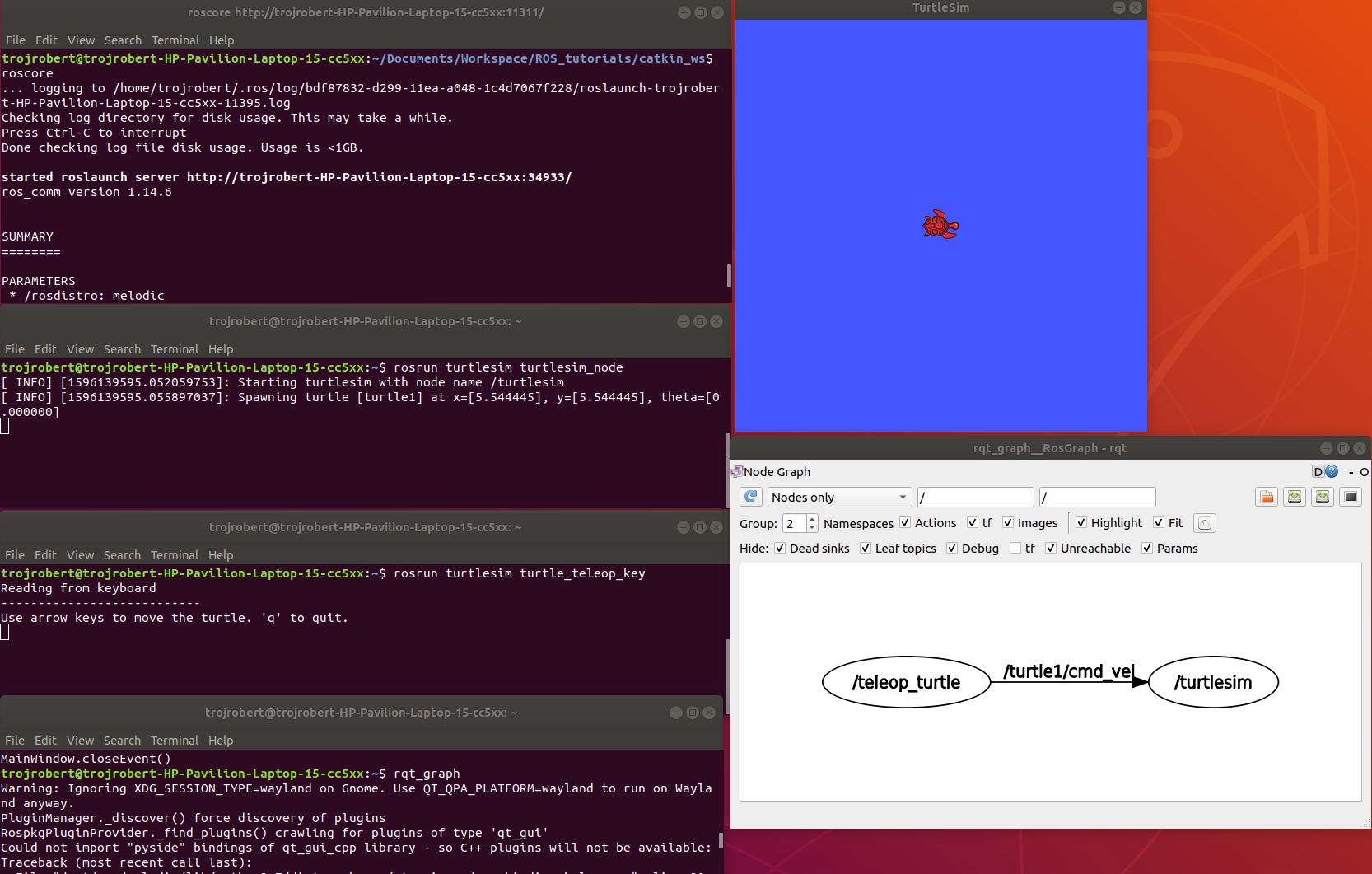
turtlesim_node display a GUI with a turtle.
Run the command on a different terminal
The turtle_teleop_key node provides a way to control the turtle with a keyboard. Click on the terminal where you ran rosrun turtlesim turtle_teleop_key, then press the arrow keys, the turtle moves in the direction of the arrow key pressed.
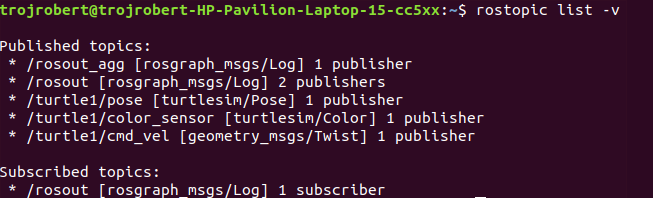
Ros Topics are the buses used by ROS nodes to exchange messages. Imagine a ROS Topic as a water pipe and ROS Message as the water, the two ends of the pipe are where the nodes are located. Topic transport message between a publisher node and a subscriber node. Ros Topics have anonymous publish/subscribe semantics. Nodes that generate message/ data publish to a specific topic, and nodes that consume or need data subscribed to a specific topic. The relationship between publishers and subscribers is many to many.
In the example above, the turtle_teleop_key node publishes the key pressed to the /turtle/cmd_vel topic and the turtlesim node subscribes to that same topic.
ROS topic command-line tool — rostopic
rostopic hz [topic] (shows how fast the messages are publishing) rostopic hz /turtle/cmd_vel
Nodes communicate by sending ROS messages to each other using ROS Topic. A message can be of primitive type integer, floating-point, boolean, etc. A publisher and subscriber should communicate using the same topic type. The topic type is determined by the message type.
Creating a ROS message
Create a msg folder in your package folder. We created a new package call bio_data_package in the example above. Inside this newly created “msg” folder, create a msg file called name.msg
Step 1
Copy the following command into the “name.msg” file. You can also check on github
Now you should have something like this, please don’t modify other lines.
Step 3
Open the CmakeList.txt file for the bio_data_package package in a text editor. This is needed for steps 3 to 6. Check a sample file on github
Modify the find_package call by adding message generation to its components. Now you should have something similar to this.
Step 4
Modify the catkin_package by adding message_runtine
Step 5
Modify add_message_files by adding the name.msg, this enable CMake to reconfigure the project with the new msg file.
Step 6
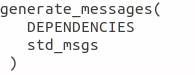
Modify generate_message by removing the # symbols to uncomment it.
Step 7
ROS message command-line tool — rosmsg
Show the description of the new message created
ROS service is one to one two way transport, it is suitable for request/reply interactions. A ROS node(server) offers a service, while another ROS node(client) requests for the service. The server sends a response back to the client. Services are defined using srv files. srv files are just like msg files, except they contain two parts: a request and a response. Services also have types like topics.
Creating a ROS Service
Create a srv folder in your package folder. You created a new package call bio_data_package in the example above. Inside this newly created “srv” folder, create a srv file called full_name.srv. A srv file is used to describe a service, srv files are stored in the “srv” folder.
Copy the following command into the “full_name.srv” file. A sample is on github
A srv file has two parts separated by -, the first part is the request while the second part is the response.
Do the steps required in creating a ROS message, but instead of Step 5, do thhe following. Please don’t repeat all the steps if you have done them before.
Step 5(specific for ROS service)
Modify add_service_files by adding the “full_name.srv”, this enables CMake to reconfigure the project with the new srv file.
ROS service command-line tool — rossrv
Show the description of the new service created
ROS Services vs ROS Topic
Involves the communication between any two nodes
Involves the communication between Publishers and Subscribers
It is a two way transport
It is a one way transport
It is one to one
It is many to many
Involves a request/ reply pattern
Does not involves a Request/reply pattern
ROS Publisher and Subscriber
Publisher and subscriber is many to many but one way transport. A node sends out a message by publishing it to a given topic. The topic is a name that is used to identify the content of the message. A node that is interested in a certain kind of data will subscribe to the appropriate topic.
Creating a Publisher
A publisher is a node that publishes messages into a topic. Create a scripts folder in your package folder, we created a new package call bio_data_package in the example above, inside this newly created “script” created folder, create a python file called writer_pub.py
Copy the following code into the “writer_pub.py” file. Sample is on github
Creating a Subscriber
A subscriber is a node that gets messages from a topic. Create a python file called reader_sub.py in the “scripts” folder.
Copy the following code into the “reader_sub.py” file. A sample is on github
Modify the caktin_install_python() call in CMameLists.txt
roswtf is a tool for diagnosing issues with a running ROS file system. It evaluates ROS setup like environment variables, packages , stacks, launch files and configuration issues.
rqt_console is a tool that displays messages being published to rosout. These messages have different level of severity like debug, info, warn, error, fatal.
Terminal 2rosrun turtlesim turtlesim_node
Terminal 3rosrun turtlesim turtle
Now move the turtle to the wall
rqt _graph
This shows nodes and the topics the nodes are communicating on.
rqt _plot
Display the scrolling time plot of data published on a topic
rqt
rqt contain most ROS GUI tools, you can select the on you want in the Plugib tab.
Other ROS concepts
ROS Launch — is used for starting and stopping multiple ros nodes. It is used to execute a ros program which is a .launch file.
ROS Stack — this contain several packages.
rosbag — published topics are saved as .bag file, rosbag command line tool is used to work with bag files.
Robot operating system is a dedicated software system for programming and controlling robots, including tools for programming, visualizing, directly interacting with hardware, and connecting robot communities around the world. In general, if you want to program and control a robot, using ROS software will make the execution much faster and less painful. And you don’t need to sit and rewrite things that others have already done, but there are things that you want to rewrite are not capable. Like Lidar or Radar driver.
ROS runs on Ubuntu, so to use ROS first you must install Linux. For those who do not know how to install Linux and ros, I have this link for you:
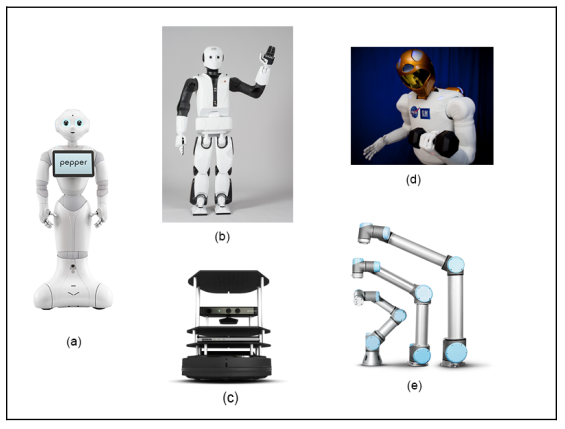
The robots and sensors supported by ROS:
The above are supported robots, starting from Pepper (a), REEM-C (b), Turtlebot (c), Robotnaut (d) and Universal robot (e). In addition, the sensors supported by ROS include LIDAR, SICK laser lms1xx, lms2xx, Hokuyo, Kinect-v2, Velodyne .., for more details, you can see the picture below.
Basic understanding of how ROS work:
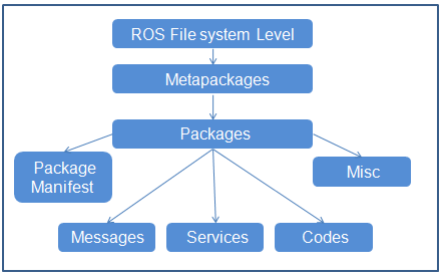
Basically ROS files are laid out and behave like this, top down in the following order, metapackages, packages, packages manifest, Misc, messages, Services, codes:
In that package (Metapackages) is a group of packages (packages) related to each other. For example, in ROS there is a total package called Navigation, this package contains all packages related to the movement of the robot, including body movement, wheels, related algorithms such as Kalman, Particle filter. … When we install the master package, it means all the sub-packages in it are also installed.
Packages (Packages), here I translate them as packages for easy understanding, the concept of packages is very important, we can say that the package is the most basic atoms that make up ROS. In one package includes, ROSnode, datasets, configuration files, source files, all bundled in one “package”. However, although there are many things in one package, but to work, we only need to care about 2 things in one package, which is the src folder, which contains our source code, and the Cmake.txt file, here is where we declare the libraries needed to execute (compile) code.
Interaction between nodes in ROS
ROS computation graph is a big picture of the interaction of nodes and topics with each other.
In the picture above, we can see that the Master is the nodes that connect all the remaining nodes.
Nodes: ROS nodes are simply the process of using the ROS API to communicate with each other. A robot may have many nodes to perform its communication. For example, a self-driving robot will have the following nodes, node that reads data from Laser scanner, Kinect camera, localization and mapping, node sends speed command to the steering wheel system.
Master: ROS master acts as an intermediate node connecting between different nodes. Master covers information about all nodes running in the ROS environment. It will swap the details of one button with the other to establish a connection between them. After exchanging information, communication will begin between the two ROS nodes. When you run a ROS program, ros_master always must run it first. You can run ros master by -> terminal-> roscore.
Message: ROS nodes can communicate with each other by sending and receiving data in the form of ROS mesage. ROS message is a data structure used by ROS nodes to exchange data. It is like a protocol, format the information sent to the nodes, such as string, float, int …
Topic: One of the methods for communicating and exchanging messages between two nodes is called ROS Topic. ROS Topic is like a message channel, in which data is exchanged by ROS message. Each topic will have a different name depending on what information it will be in charge of providing. One Node will publish information for a Topic and another node can read from the Topic by subcrible to it. Just like you want to watch your videos, you must subcrible your channel. If you want to see which topics you are running on, the command is rostopic list, if you want to see a certain topic see what nodes are publishing or subcrible on it. Then the command is rostopic info / terntopic. If you want to see if there is anything in that topic, type rostopic echo / terntopic.
Service: Service is a different type of communication method from Topic. Topic uses a publish or subcrible interaction, but in the service, it interacts in a request – response fashion. This is exactly like the network side. One node will act as a server, there is a permanent server run and when the Node client sends a service request to the server. The server will perform the service and send the result to the client. The client node must wait until the server responds with the result. The server is especially useful when we need to execute something that takes a long time to process, so we leave it on the server, when we need it we call.
PID control is one of the most important ideas in control engineering. Even though modern self-driving systems use many advanced models, PID is still a valuable tool because it is simple, interpretable, and effective for many feedback problems.
What PID Means
PID stands for Proportional, Integral, and Derivative. These three terms work together to reduce the error between a target value and the current value.
P reacts to the current error.
I reacts to accumulated past error.
D reacts to the rate of change of the error.
A Driving Example
Imagine a vehicle that should stay at the center of the lane. The lateral distance from the lane center is called the cross-track error.
A very simple steering rule can be written like this:
If the car drifts to the right, the error becomes positive and the controller applies a steering correction to bring it back.
Why Each Term Matters
Proportional gives immediate correction, but too much gain can cause oscillation.
Integral helps remove steady-state bias, for example when the car consistently stays slightly off-center.
Derivative damps fast changes and can reduce overshoot.
A Simple Python Example
Kp, Ki, Kd = 0.2, 0.01, 1.5
integral = 0.0
previous_error = 0.0
def pid_step(error, dt):
global integral, previous_error
integral += error * dt
derivative = (error - previous_error) / dt
previous_error = error
return -(Kp * error + Ki * integral + Kd * derivative)
Tuning Tips
Start with Kp only and increase it slowly.
Add Kd if the system oscillates too much.
Add a small Ki only if steady-state error remains.
Test with realistic noise and changing speed, not only ideal conditions.
Final Thoughts
PID control is not the whole story in autonomous driving, but it is still one of the best places to learn feedback control. It gives you intuition that will help later with more advanced controllers such as MPC.
The pseudocode below outlines an implementation of the A* search algorithm using the bicycle model. The following variables and objects are used in the code but not defined there:
State(x, y, theta, g, f): An object which stores x, y coordinates, direction theta, and current g and f values.
grid: A 2D array of 0s and 1s indicating the area to be searched. 1s correspond to obstacles, and 0s correspond to free space.
SPEED: The speed of the vehicle used in the bicycle model.
LENGTH: The length of the vehicle used in the bicycle model.
NUM_THETA_CELLS: The number of cells a circle is divided into. This is used in keeping track of which States we have visited already.
The bulk of the hybrid A* algorithm is contained within the search function. The expand function takes a state and goal as inputs and returns a list of possible next states for a range of steering angles. This function contains the implementation of the bicycle model and the call to the A* heuristic function.
def expand(state, goal):
next_states = []
for delta in range(-35, 40, 5):
# Create a trajectory with delta as the steering angle using
# the bicycle model:
# ---Begin bicycle model---
delta_rad = deg_to_rad(delta)
omega = SPEED/LENGTH * tan(delta_rad)
next_x = state.x + SPEED * cos(theta)
next_y = state.y + SPEED * sin(theta)
next_theta = normalize(state.theta + omega)
# ---End bicycle model-----
next_g = state.g + 1
next_f = next_g + heuristic(next_x, next_y, goal)
# Create a new State object with all of the "next" values.
state = State(next_x, next_y, next_theta, next_g, next_f)
next_states.append(state)
return next_states
def search(grid, start, goal):
# The opened array keeps track of the stack of States objects we are
# searching through.
opened = []
# 3D array of zeros with dimensions:
# (NUM_THETA_CELLS, grid x size, grid y size).
closed = [[[0 for x in range(grid[0])] for y in range(len(grid))]
for cell in range(NUM_THETA_CELLS)]
# 3D array with same dimensions. Will be filled with State() objects
# to keep track of the path through the grid.
came_from = [[[0 for x in range(grid[0])] for y in range(len(grid))]
for cell in range(NUM_THETA_CELLS)]
# Create new state object to start the search with.
x = start.x
y = start.y
theta = start.theta
g = 0
f = heuristic(start.x, start.y, goal)
state = State(x, y, theta, 0, f)
opened.append(state)
# The range from 0 to 2pi has been discretized into NUM_THETA_CELLS cells.
# Here, theta_to_stack_number returns the cell that theta belongs to.
# Smaller thetas (close to 0 when normalized into the range from 0 to
# 2pi) have lower stack numbers, and larger thetas (close to 2pi when
# normalized) have larger stack numbers.
stack_num = theta_to_stack_number(state.theta)
closed[stack_num][index(state.x)][index(state.y)] = 1
# Store our starting state. For other states, we will store the previous
# state in the path, but the starting state has no previous.
came_from[stack_num][index(state.x)][index(state.y)] = state
# While there are still states to explore:
while opened:
# Sort the states by f-value and start search using the state with the
# lowest f-value. This is crucial to the A* algorithm; the f-value
# improves search efficiency by indicating where to look first.
opened.sort(key=lambda state:state.f)
current = opened.pop(0)
# Check if the x and y coordinates are in the same grid cell
# as the goal. (Note: The idx function returns the grid index for
# a given coordinate.)
if (idx(current.x) == goal[0]) and (idx(current.y) == goal.y):
# If so, the trajectory has reached the goal.
return path
# Otherwise, expand the current state to get a list of possible
# next states.
next_states = expand(current, goal)
for next_s in next_states:
# If we have expanded outside the grid, skip this next_s.
if next_s is not in the grid:
continue
# Otherwise, check that we haven't already visited this cell and
# that there is not an obstacle in the grid there.
stack_num = theta_to_stack_number(next_s.theta)
if closed[stack_num][idx(next_s.x)][idx(next_s.y)] == 0
and grid[idx(next_s.x)][idx(next_s.y)] == 0:
# The state can be added to the opened stack.
opened.append(next_s)
# The stack_number, idx(next_s.x), idx(next_s.y) tuple
# has now been visited, so it can be closed.
closed[stack_num][idx(next_s.x)][idx(next_s.y)] = 1
# The next_s came from the current state, and is recorded.
came_from[stack_num][idx(next_s.x)][idx(next_s.y)] = current
Now we go to next step:
Implementing Hybrid A*
In this exercise, you will be provided a working implementation of a breadth first search algorithm which does not use any heuristics to improve its efficiency. Your goal is to try to make the appropriate modifications to the algorithm so that it takes advantage of heuristic functions (possibly the ones mentioned in the previous paper) to reduce the number of grid cell expansions required.
Instructions:
Modify the code in ‘hybrid_breadth_first.cpp’ and hit Test Run to check your results.
Note the number of expansions required to solve an empty 15×15 grid (it should be about 18,000!). Modify the code to try to reduce that number. How small can you get it?
Solution:
#include <iostream>
#include <vector>
#include "hybrid_breadth_first.h"
using std::cout;
using std::endl;
// Sets up maze grid
int X = 1;
int _ = 0;
/**
* TODO: You can change up the grid maze to test different expansions.
*/
vector<vector<int>> GRID = {
{_,X,X,_,_,_,_,_,_,_,X,X,_,_,_,_,},
{_,X,X,_,_,_,_,_,_,X,X,_,_,_,_,_,},
{_,X,X,_,_,_,_,_,X,X,_,_,_,_,_,_,},
{_,X,X,_,_,_,_,X,X,_,_,_,X,X,X,_,},
{_,X,X,_,_,_,X,X,_,_,_,X,X,X,_,_,},
{_,X,X,_,_,X,X,_,_,_,X,X,X,_,_,_,},
{_,X,X,_,X,X,_,_,_,X,X,X,_,_,_,_,},
{_,X,X,X,X,_,_,_,X,X,X,_,_,_,_,_,},
{_,X,X,X,_,_,_,X,X,X,_,_,_,_,_,_,},
{_,X,X,_,_,_,X,X,X,_,_,X,X,X,X,X,},
{_,X,_,_,_,X,X,X,_,_,X,X,X,X,X,X,},
{_,_,_,_,X,X,X,_,_,X,X,X,X,X,X,X,},
{_,_,_,X,X,X,_,_,X,X,X,X,X,X,X,X,},
{_,_,X,X,X,_,_,X,X,X,X,X,X,X,X,X,},
{_,X,X,X,_,_,_,_,_,_,_,_,_,_,_,_,},
{X,X,X,_,_,_,_,_,_,_,_,_,_,_,_,_,}};
vector<double> START = {0.0,0.0,0.0};
vector<int> GOAL = {(int)GRID.size()-1, (int)GRID[0].size()-1};
int main() {
cout << "Finding path through grid:" << endl;
// Creates an Empty Maze and for testing the number of expansions with it
for(int i = 0; i < GRID.size(); ++i) {
cout << GRID[i][0];
for(int j = 1; j < GRID[0].size(); ++j) {
cout << "," << GRID[i][j];
}
cout << endl;
}
HBF hbf = HBF();
HBF::maze_path get_path = hbf.search(GRID,START,GOAL);
vector<HBF::maze_s> show_path = hbf.reconstruct_path(get_path.came_from,
START, get_path.final);
cout << "show path from start to finish" << endl;
for(int i = show_path.size()-1; i >= 0; --i) {
HBF::maze_s step = show_path[i];
cout << "##### step " << step.g << " #####" << endl;
cout << "x " << step.x << endl;
cout << "y " << step.y << endl;
cout << "theta " << step.theta << endl;
}
return 0;
}