YOLO hẳn đã rất quen thuộc với các bạn trẻ, chúng ta đã nghe từ này biết bao nhiêu lần, khi mà thằng bạn của bạn muốn đua xe đập đá mà bạn ngăn cản, nó sẽ lôi từ này để bật lại bạn, rằng mày chỉ sống có 1 lần thôi, yolo đi.
Câu đó thật ra cũng đúng trong hoàn cảnh bạn biết mình làm gì:)), và trong bài viết này mình cũng nói về YOLO, nhưng không phải về cụm từ kia, mà là một thành tựu lớn của neural network và Image Processing- YOLO( You Only Look One). Nghĩa là chỉ nhìn một lần thôi, lần đầu nghe câu này mình thấy buồn cười, thì hiển nhiên là nhìn một lần chứ mấy lần, còn thấy người đẹp muốn nhìn lại mấy lần thì nhìn chứ, ai cấm:)). Nhưng thật ra câu nói này không phải cho con người, mà là cho computer. Nếu bạn nào đã có kiến thức về Image Processing thì mời lướt qua, còn chưa thì mình diễn tả nôm na như sau: Máy tính nhìn một bức ảnh dưới dạng một ma trận số, và để thực hiện một số tính năng chỉnh sửa ảnh, đầu tiên ta phải xét đến một filter matrix hoặc còn gọi là convolution, convolution matrix này sẽ được nhân với một ô nhỏ trên cùng bên trái của tấm ảnh, sau đó ô này sẽ trượt theo chiều ngang và sau đó xuống dòng đến khi đi hết tấm ảnh. Do đó có thể nói máy tính nó không nhìn tấm ảnh một lần như chúng ta mà nó nhìn từ trái qua phải từ trên xuống dưới. Tất nhiên nhìn kĩ là tốt nhưng làm vậy rất tốn thời gian, trong khi chúng ta chỉ cần nhỉn tổng thể bức hình là có thể chỉ ra trong đó có gì, thì computer cần phải rà hàng trăm hàng ngàn tấm ảnh nhỏ mới làm được điều tương tự. YOLO ra đời để cho phép máy tính làm điều tương tự nhưng tốc độ được cải thiện đáng kể, chỉ quét một lần và nhận diện objects, cho đó nâng cao tốc độ xử lý ảnh lên đến 60 frames/s nhờ đó có thể đáp ứng nhu cầu real-time.
Dưới đây là một số chia sẻ của chính tác giả YOLO:
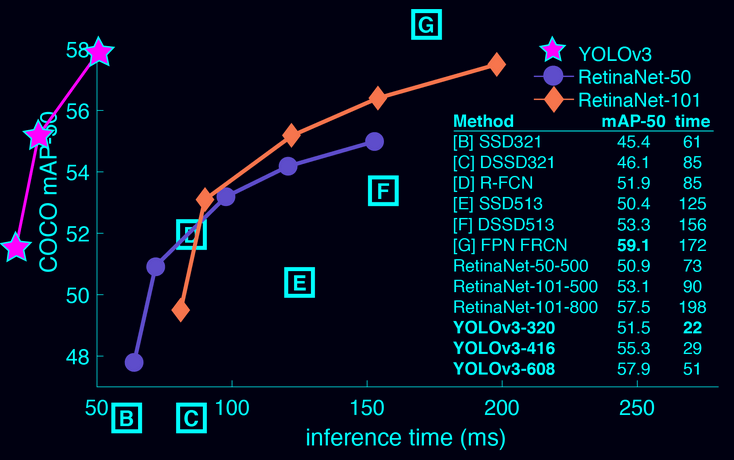
You only look once (YOLO) is a state-of-the-art, real-time object detection system. On a Pascal Titan X it processes images at 30 FPS and has a mAP of 57.9% on COCO test-dev.
Prior detection systems repurpose classifiers or localizers to perform detection. They apply the model to an image at multiple locations and scales. High scoring regions of the image are considered detections.
We use a totally different approach. We apply a single neural network to the full image. This network divides the image into regions and predicts bounding boxes and probabilities for each region. These bounding boxes are weighted by the predicted probabilities.
Về cách hoạt động của YOLO mình đã nói ở trên, còn hình bên dưới chính là kết quả hoành tráng mà nó tạo ra. Trong hình bạn có thể thất từng chiếc xe được theo dấu với những hộp bao quanh, và xác định nó là xe lên tới 99%. Không những vậy, đoạn code còn kết hợp với segmentation để nhận dạng đường biên của mỗi chiếc xe, giúp nhận diện chính xác hơn.

Nếu các bạn có hứng thú với đoạn code trong video bên trên, bạn có thể lấy code qua Github của mình, đoạn code được viết bằng Python và sử dụng tensorflow model.
