Robot operating system is a dedicated software system for programming and controlling robots, including tools for programming, visualizing, directly interacting with hardware, and connecting robot communities around the world. In general, if you want to program and control a robot, using ROS software will make the execution much faster and less painful. And you don’t need to sit and rewrite things that others have already done, but there are things that you want to rewrite are not capable. Like Lidar or Radar driver.
ROS runs on Ubuntu, so to use ROS first you must install Linux. For those who do not know how to install Linux and ros, I have this link for you:
The robots and sensors supported by ROS:
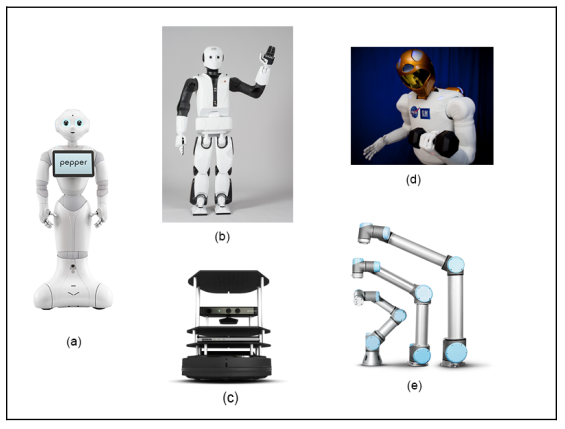
The above are supported robots, starting from Pepper (a), REEM-C (b), Turtlebot (c), Robotnaut (d) and Universal robot (e). In addition, the sensors supported by ROS include LIDAR, SICK laser lms1xx, lms2xx, Hokuyo, Kinect-v2, Velodyne .., for more details, you can see the picture below.

Basic understanding of how ROS work:
Basically ROS files are laid out and behave like this, top down in the following order, metapackages, packages, packages manifest, Misc, messages, Services, codes:
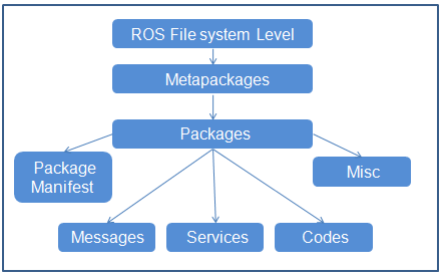
In that package (Metapackages) is a group of packages (packages) related to each other. For example, in ROS there is a total package called Navigation, this package contains all packages related to the movement of the robot, including body movement, wheels, related algorithms such as Kalman, Particle filter. … When we install the master package, it means all the sub-packages in it are also installed.

Packages (Packages), here I translate them as packages for easy understanding, the concept of packages is very important, we can say that the package is the most basic atoms that make up ROS. In one package includes, ROSnode, datasets, configuration files, source files, all bundled in one “package”. However, although there are many things in one package, but to work, we only need to care about 2 things in one package, which is the src folder, which contains our source code, and the Cmake.txt file, here is where we declare the libraries needed to execute (compile) code.
Interaction between nodes in ROS
ROS computation graph is a big picture of the interaction of nodes and topics with each other.
In the picture above, we can see that the Master is the nodes that connect all the remaining nodes.
Nodes: ROS nodes are simply the process of using the ROS API to communicate with each other. A robot may have many nodes to perform its communication. For example, a self-driving robot will have the following nodes, node that reads data from Laser scanner, Kinect camera, localization and mapping, node sends speed command to the steering wheel system.
Master: ROS master acts as an intermediate node connecting between different nodes. Master covers information about all nodes running in the ROS environment. It will swap the details of one button with the other to establish a connection between them. After exchanging information, communication will begin between the two ROS nodes. When you run a ROS program, ros_master always must run it first. You can run ros master by -> terminal-> roscore.
Message: ROS nodes can communicate with each other by sending and receiving data in the form of ROS mesage. ROS message is a data structure used by ROS nodes to exchange data. It is like a protocol, format the information sent to the nodes, such as string, float, int …
Topic: One of the methods for communicating and exchanging messages between two nodes is called ROS Topic. ROS Topic is like a message channel, in which data is exchanged by ROS message. Each topic will have a different name depending on what information it will be in charge of providing. One Node will publish information for a Topic and another node can read from the Topic by subcrible to it. Just like you want to watch your videos, you must subcrible your channel. If you want to see which topics you are running on, the command is rostopic list, if you want to see a certain topic see what nodes are publishing or subcrible on it. Then the command is rostopic info / terntopic. If you want to see if there is anything in that topic, type rostopic echo / terntopic.
Service: Service is a different type of communication method from Topic. Topic
uses a publish or subcrible interaction, but in the service, it interacts in a request – response fashion. This is exactly like the network side. One node will act as a server, there is a permanent server
run and when the Node client sends a service request to the server. The server will perform the service and send the result to the client. The client node must wait until the server responds with the result. The server is especially useful when we need to execute something that takes a long time to process, so we leave it on the server, when we need it we call.