
Load Data
Load the MNIST data, which comes pre-loaded with TensorFlow.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", reshape=False)
X_train, y_train = mnist.train.images, mnist.train.labels
X_validation, y_validation = mnist.validation.images, mnist.validation.labels
X_test, y_test = mnist.test.images, mnist.test.labels
assert(len(X_train) == len(y_train))
assert(len(X_validation) == len(y_validation))
assert(len(X_test) == len(y_test))
print()
print("Image Shape: {}".format(X_train[0].shape))
print()
print("Training Set: {} samples".format(len(X_train)))
print("Validation Set: {} samples".format(len(X_validation)))
print("Test Set: {} samples".format(len(X_test)))
The MNIST data that TensorFlow pre-loads comes as 28x28x1 images.
However, the LeNet architecture only accepts 32x32xC images, where C is the number of color channels.
In order to reformat the MNIST data into a shape that LeNet will accept, we pad the data with two rows of zeros on the top and bottom, and two columns of zeros on the left and right (28+2+2 = 32).
You do not need to modify this section.
import numpy as np
# Pad images with 0s
X_train = np.pad(X_train, ((0,0),(2,2),(2,2),(0,0)), 'constant')
X_validation = np.pad(X_validation, ((0,0),(2,2),(2,2),(0,0)), 'constant')
X_test = np.pad(X_test, ((0,0),(2,2),(2,2),(0,0)), 'constant')
print("Updated Image Shape: {}".format(X_train[0].shape))
Visualize Data
View a sample from the dataset.
You do not need to modify this section.
import random
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
index = random.randint(0, len(X_train))
image = X_train[index].squeeze()
plt.figure(figsize=(1,1))
plt.imshow(image, cmap="gray")
print(y_train[index])
Preprocess Data
Shuffle the training data.
You do not need to modify this section.
from sklearn.utils import shuffle
X_train, y_train = shuffle(X_train, y_train)
Setup TensorFlow
The EPOCH and BATCH_SIZE values affect the training speed and model accuracy.
You do not need to modify this section.In [ ]:
import tensorflow as tf
EPOCHS <strong>=</strong> 10
BATCH_SIZE <strong>=</strong> 128
TODO: Implement LeNet-5
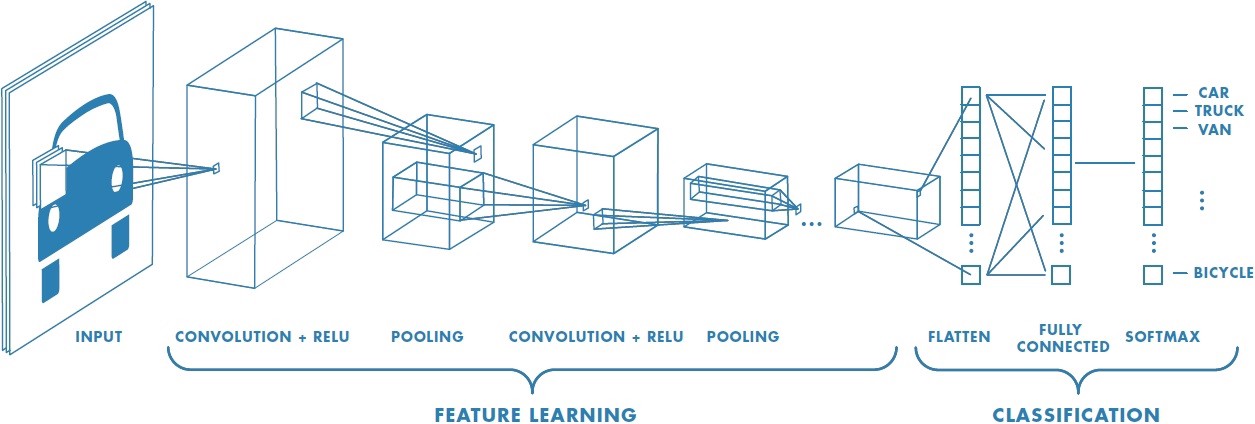
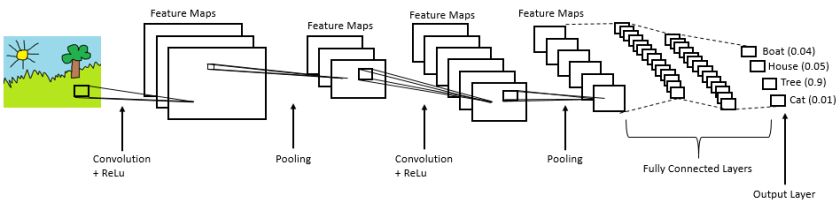
Implement the LeNet-5 neural network architecture.
This is the only cell you need to edit.
Input
The LeNet architecture accepts a 32x32xC image as input, where C is the number of color channels. Since MNIST images are grayscale, C is 1 in this case.
Architecture
Layer 1: Convolutional. The output shape should be 28x28x6.
Activation. Your choice of activation function.
Pooling. The output shape should be 14x14x6.
Layer 2: Convolutional. The output shape should be 10x10x16.
Activation. Your choice of activation function.
Pooling. The output shape should be 5x5x16.
Flatten. Flatten the output shape of the final pooling layer such that it’s 1D instead of 3D. The easiest way to do is by using tf.contrib.layers.flatten, which is already imported for you.
Layer 3: Fully Connected. This should have 120 outputs.
Activation. Your choice of activation function.
Layer 4: Fully Connected. This should have 84 outputs.
Activation. Your choice of activation function.
Layer 5: Fully Connected (Logits). This should have 10 outputs.
Output
Return the result of the 2nd fully connected layer.
from tensorflow.contrib.layers import flatten
def LeNet(x):
# Arguments used for tf.truncated_normal, randomly defines variables for the weights and biases for each layer
mu = 0
sigma = 0.1
<code># TODO: Layer 1: Convolutional. Input = 32x32x1. Output = 28x28x6. # TODO: Activation. # TODO: Pooling. Input = 28x28x6. Output = 14x14x6. # TODO: Layer 2: Convolutional. Output = 10x10x16. # TODO: Activation. # TODO: Pooling. Input = 10x10x16. Output = 5x5x16. # TODO: Flatten. Input = 5x5x16. Output = 400. # TODO: Layer 3: Fully Connected. Input = 400. Output = 120. # TODO: Activation. # TODO: Layer 4: Fully Connected. Input = 120. Output = 84. # TODO: Activation. # TODO: Layer 5: Fully Connected. Input = 84. Output = 10. return logits</code>
Features and Labels
Train LeNet to classify MNIST data.
x is a placeholder for a batch of input images. y is a placeholder for a batch of output labels.
You do not need to modify this section.
x = tf.placeholder(tf.float32, (None, 32, 32, 1))
y = tf.placeholder(tf.int32, (None))
one_hot_y = tf.one_hot(y, 10)












































{kind=link}